The transition to microservices was meant to unlock engineering velocity and team autonomy. Instead, for many organizations, it has inadvertently created a developer productivity crisis—a multi-million-dollar operational drag hidden within engineering budgets. The problem isn’t that testing is inherently difficult; it’s that the traditional testing models designed for monoliths are fundamentally incompatible with the distributed, asynchronous nature of modern architectures.
Recent research reveals a stark reality: 97% of developers report losing significant time to inefficiencies, with a staggering 69% losing eight or more hours every week. This lost time translates directly into a financial crisis. For an engineering organization with 200 developers, this inefficiency can equate to over $400,000 in squandered productivity every single month, a figure derived from real-world analysis of teams grappling with integration failures. This isn’t a minor inconvenience; it’s a systemic drain on innovation, morale, and the bottom line.
The root of this crisis lies in a simple fact: testing complexity doesn’t grow linearly with the number of services—it grows exponentially. An approach that works for five services becomes an unmanageable bottleneck at 50. This exponential growth is driven by a trifecta of compounding factors: the rapid multiplication of integration points between services, the unsustainable maintenance burden of mock data and virtualized services, and the spiraling infrastructure costs of duplicating environments for testing.
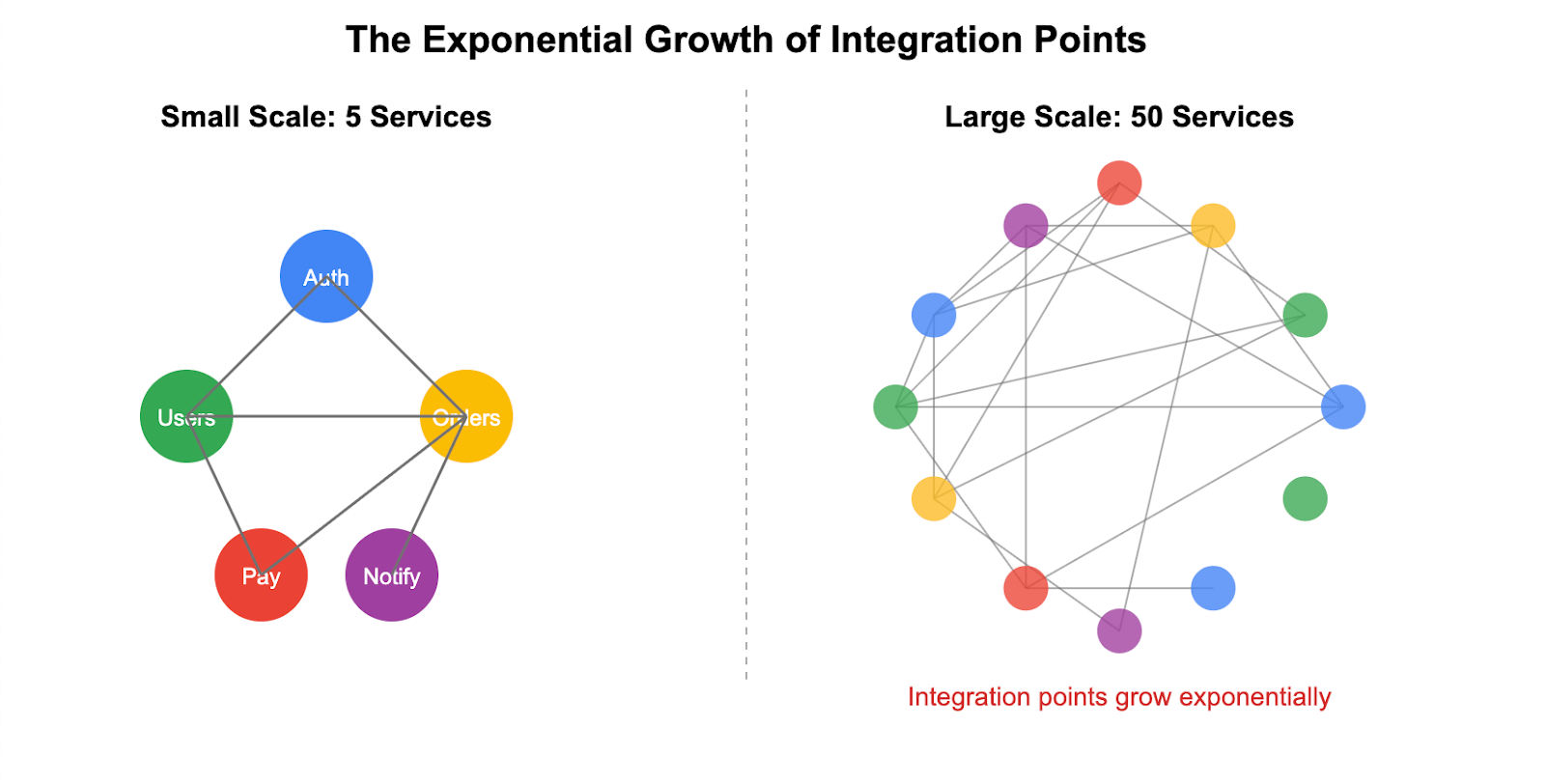
This leads to the microservices testing paradox: the very attributes that make the architecture so appealing—independence, scalability, and team autonomy—are precisely what make testing it exponentially harder. Each independently deployable service adds a new node to a complex web of dependencies, creating a combinatorial explosion of test scenarios that must be validated. The result is a system where individual components are simple, but the whole is infinitely complex, with multiple versions, communication paths, and failure points coexisting in production. The productivity loss felt by developers is merely a lagging indicator of this deeper architectural mismatch. The pain points they cite—technical debt, complex build processes, and constant context switching—are symptoms of a fundamental strategic error: applying monolithic testing patterns to a post-monolith world.
With cloud-native adoption now at 89%, it’s clear that traditional approaches are not just inefficient; they are fundamentally broken. This guide serves as the definitive resource to bridge the gap between testing theory and practical, scalable implementation, detailing a new paradigm that resolves the million-dollar problem of slow microservices testing. For more background on the financial impact, see “The Million-Dollar Problem of Slow Microservices Testing.”
The long-held dream of running a complete, production-like environment on a developer’s laptop is officially over. For any modern cloud-native application, which can easily comprise 10 to 50 distinct microservices, running the entire stack locally is impractical due to resource constraints. This reality forces developers into a compromised position, where they must rely on simulations and stubs that create a dangerous gap between the local development experience and production reality, leading to a cascade of downstream failures.
This gives rise to the “works on my machine” fallacy, where code that passes local checks fails catastrophically during integration. The traditional approaches used to bridge this gap are themselves deeply flawed, especially at scale.
The true goal of local development is not merely to write code but to validate interactions. The critical feedback loop for a microservice developer is not just “does my code compile?” but “does my service interact correctly with its dependencies?” Traditional methods fail to provide this feedback reliably.
A paradigm shift is required: from attempting to replicate the cloud on a laptop to enabling a local service to participate in a shared cloud environment. This is achieved through request-level isolation. In this model, a developer runs only the single service they are actively working on locally. A lightweight tool then intelligently routes specific test requests from the shared Kubernetes cluster to their local machine. All other requests for downstream dependencies are seamlessly routed to the live, up-to-date services running in that shared cluster.20
This approach transforms both developer experience and cost structures. Instead of hours spent debugging configuration drift, developers get connected to a high-fidelity environment in seconds. The cost model shifts dramatically as well. Traditional full-stack duplication for each developer can cost anywhere from $10,000 to $50,000 per month. The sandbox model, which leverages a shared baseline, eliminates this redundant infrastructure spend. As Martin Fowler notes, the test pyramid for distributed systems requires a more robust and reliable integration test layer. By bringing high-fidelity interaction testing into the developer’s inner loop, this modern approach finally delivers on that need.
For more information on this approach, explore “Local Development” and this overview on “How to Test Microservices.”
The pull request (PR) is the most critical quality gate in the software development lifecycle. It’s the last line of defense before a change is merged into the main branch. Yet, testing at this stage has long been a frustrating trade-off between speed and fidelity. Full end-to-end tests are too slow, taking hours to run, while tests using mocks are fast but unreliable. The future of PR testing lies in a new approach: AI-powered analysis that delivers fast, high-fidelity feedback without the crushing maintenance burden of traditional contract testing.
The goal is clear: provide a developer and their reviewer with production-like feedback on a change within 5-10 minutes. Anything longer breaks the flow of the review process and pushes critical validation downstream, where fixing bugs is exponentially more expensive.
Traditional consumer-driven contract testing, popularized by tools like Pact, was an early attempt to solve this. The idea is to have a “contract” that defines the expected interactions between a service consumer and a provider. While valuable in principle, this approach suffers from significant drawbacks at scale:
The breakthrough comes from evolving beyond manual contract definition to AI-powered behavioral analysis. With a solution like Signadot’s SmartTests, the workflow is fundamentally simplified. Instead of writing complex contracts, a developer writes a simple test in a language like Starlark to invoke an API endpoint. This test is then automatically executed against both the existing baseline version of the service and the new version running in an isolated sandbox.
The core innovation is the ” Smart Diff” technology. An AI model analyzes and compares the responses from the two versions. Crucially, it has been trained to distinguish meaningful, breaking changes—such as a removed field, a changed data type, or a different status code—from benign “noise” like updated timestamps, newly generated IDs, or a different ordering of elements in an array. This intelligent filtering eliminates the false positives and test flakiness that plague traditional systems. The value of AI here is not just automation, but
attention filtering. It automates the cognitive load of sifting through irrelevant data, focusing the developer’s scarce attention only on the changes that truly matter.
This represents a shift from static contract validation to dynamic behavioral validation. By observing the service’s actual runtime behavior against real dependencies, this method catches subtle issues that static analysis misses. The results are transformative. Teams using this approach have achieved
10x faster feedback cycles. DoorDash, for instance, used this model to slash their feedback time on changes from over 30 minutes to less than two minutes. This turns the PR from a simple code review into a comprehensive, automated integration validation gate.
To learn more about this technology, see this guide on “AI-powered Contract Testing.”
For most organizations that have adopted microservices, the CI/CD pipeline—once the engine of velocity—has become the primary bottleneck. The traditional pipeline model, designed for monoliths, forces system-wide integration tests into a slow, sequential, post-merge process. This creates the infamous “staging bottleneck,” a perpetual queue of developers waiting for a stable window to test their changes, which kills productivity and strangles the very agility microservices promised.
The problem lies in an unsustainable scaling model. In a traditional setup, the cost and complexity of test environments follow a painful equation: Cost∝(#of Developers×#of Services). Each new developer and each new service multiplies the need for dedicated test infrastructure, leading to runaway cloud bills and operational overhead.4 This forces a false choice between exorbitant costs for many environments or a productivity-killing bottleneck with just a few.
The modern solution is to break this model by leveraging sandboxes to enable parallel execution at scale. This introduces a revolutionary new cost equation: Cost∝(#of Developers+#of Services). This is an architectural breakthrough that decouples infrastructure costs from team and service growth by intelligently sharing resources.
This new paradigm redefines the CI/CD workflow and the purpose of the pipeline itself.
This transformation has a direct and measurable impact on the four key DORA metrics, the industry standard for measuring DevOps performance.
This approach is not a niche solution; it is a platform engineering best practice for the modern enterprise. With 89% of organizations now using cloud-native technologies and 93% using or evaluating Kubernetes, solving the CI/CD bottleneck is a central challenge for the vast majority of engineering teams.
For more details, explore guides on our docs.
The concept of a persistent, shared “staging” environment is a relic of the monolithic era. In a world of distributed microservices, it has become a costly, inefficient, and fundamentally flawed model for integration testing. The future is not about building more perfect replicas of production; it’s about eliminating the need for replication altogether through a paradigm shift towards dynamic, on-demand, request-level isolation.
The staging environment has become a crisis point for many engineering organizations. Imagine a scenario where 20 teams collectively need 80 hours of testing time per week, but the shared staging environment only offers 40 hours of stable uptime due to constant deployments, data corruption, and breakages. The result is a perpetual traffic jam of developers waiting in line to validate their changes.
This bottleneck is not just a productivity issue; it’s a massive financial drain. The model of full environment duplication—cloning the entire production stack for testing—is astronomically expensive. A 50-developer team can easily spend over $561,000 annually just to maintain a single, full-sized staging environment.36 In a high-growth company like Brex, the cost for their homegrown preview environment system, which replicated the stack for each developer, ballooned to $4 million per year before they adopted a new approach. This sentiment is echoed by industry leaders like Kelsey Hightower, who has noted that staging environments are, at best, a pale and untrustworthy imitation of the real production environment.
The solution lies in a fundamental paradigm shift from Infrastructure-Level Isolation to Request-Level Isolation.
This is enabled by a technology called header-based context propagation. When a test begins, a unique context identifier (e.g., a specific HTTP header) is injected into the initial request. As this request travels through the microservices ecosystem, a service mesh or lightweight SDK in each service inspects the header. Based on the context, it dynamically routes the request to either a sandboxed version of a service (for the code under test) or the shared, baseline version of its dependencies.
The advantages of this approach become clear when compared directly with traditional methods.
| Approach | Isolation Model | Spin-up Time | Infrastructure Cost | Production Fidelity | Scalability |
|---|---|---|---|---|---|
| Traditional Staging | None (Shared) | N/A (Always on) | Very High | Low (Stale data/config) | Poor (Bottleneck) |
| Mocking/Virtualization | N/A (Simulation) | Milliseconds | Very Low | Very Low (Drifts from reality) | N/A |
| Full Duplication (Okteto/Qovery) | Infrastructure-level | Minutes to Hours | High (Cost ∝ Devs × Services) | Medium (Hard to sync data) | Poor (Cost prohibitive) |
| Signadot Sandboxes | Request-Level | Seconds | Low (Cost ∝ Devs + Services) | High (Live dependencies) | Excellent (Parallel) |
The return on investment (ROI) from this shift is not theoretical. It’s proven by leading technology companies:
To learn more, see this Guide to Ephemeral Environments in Kubernetes and explore our case studies.
In the world of complex, distributed systems, the idea that all bugs can be caught before deployment is a dangerous fiction. The boundary between testing and production is blurring, and mature engineering organizations embrace this reality. They understand that production is the ultimate testing ground. This philosophy, often called “testing in production,” is not about recklessness; it’s about systematically and safely validating changes in the only environment that truly matters—the one serving live users.
As technologist Kelsey Hightower has pointed out, “Organizations are always testing in production, whether they deliberately choose to or not”. The critical difference lies in doing so accidentally and reactively versus intentionally and proactively. The most resilient companies have adopted a suite of practices to test in production with confidence.
These advanced production practices do not replace pre-production testing; they depend on it. This is where a robust sandbox strategy becomes a critical enabler. The purpose of modern testing is not to prevent all failure, which is impossible in a complex system, but to build the confidence to ship changes and recover quickly when failures inevitably occur.
When a team has already validated a change in a high-fidelity sandbox, they have high confidence that it doesn’t break API contracts or core integrations—these are the “known unknowns.” This rigorous pre-production check de-risks the initial deployment, allowing production testing techniques like canaries and chaos experiments to focus on discovering emergent, at-scale issues—the “unknown unknowns” like cascading failures, performance degradation under specific load patterns, or unexpected user behaviors.
This entire lifecycle is orchestrated by a modern platform engineering team, which provides a unified toolchain for testing, monitoring, and debugging. The feedback loop becomes continuous: insights from production observability—traces, metrics, and logs—are used to create more effective sandbox tests, creating a virtuous cycle of improvement. This observability-driven testing is the hallmark of a mature, high-performing engineering organization.
The evolution of microservices testing is not about making incremental improvements to outdated tools. It represents a fundamental paradigm shift toward an integrated, intelligent, and developer-centric platform. This transformation is being driven by three powerful forces: the organizational shift to platform engineering, the technological shift to AI-driven validation, and the cultural shift that recognizes developer experience (DevEx) as a primary competitive advantage.
First, the operating model of engineering is changing. The old world of siloed Dev, QA, and Ops teams is giving way to a centralized platform engineering model. In this model, a platform team is responsible for providing self-service tools, automation, and standardized “golden paths” that enable product teams to deliver value quickly and safely. This trend is accelerating rapidly, with 53% of organizations having started their platform engineering journey in 2024. This organizational structure demands a unified, platform-based solution for testing, not a fragmented collection of point tools.
Second, the technology of testing is becoming intelligent. The future is not just about automating test execution but about automating analysis and insight. Signadot’s SmartTests are at the vanguard of this movement. By using AI to analyze the behavior of services and distinguish meaningful changes from benign noise, it eliminates the test maintenance and flakiness that plague traditional contract testing. This is the technological leap that makes scalable, low-friction testing a reality.
Finally, the industry has recognized that the “Million-Dollar Testing Crisis” is, at its core, a developer experience (DevEx) crisis. Slow feedback loops, brittle environments, and constant context switching lead to developer frustration, burnout, and attrition. A superior testing platform that provides self-service capabilities, sub-second environment creation, and production-fidelity feedback is no longer a luxury. It is a critical tool for attracting and retaining elite engineering talent and maximizing their productivity and satisfaction. The decision-making process for testing tools is therefore elevating from a tactical, team-level choice to a strategic, platform-level investment.
To make the business case for this transformation, organizations can use a simple ROI framework to calculate their own “Cost of Inefficiency.”
Cost of Wasted Developer Time: Calculate the productivity drain from testing bottlenecks.
Costwasted=(Number of Developers)×(Hours Lost per Week)×(52)×(Fully Loaded Hourly Cost)
Cost of Infrastructure Waste: Calculate the savings from eliminating redundant environments. A 90% reduction in infrastructure costs is achievable in cases where teams are duplicating full environments for each test or developer workflow. In scenarios where multiple static environments exist (dev, QA, staging, etc.), consolidation into a shared pool of ephemeral environments can still yield over 50% cost savings.
Costsavings=(Annual Cost of Staging/Preview Environments)×0.90
Beyond infrastructure savings, teams see significant quality improvements. By catching defects earlier, Signadot can prevent bugs from ever reaching staging (saving roughly $1,500 per bug) and production (avoiding incidents that can cost $10,000 or more each). These reductions compound over time, lowering both direct remediation costs and the downstream impact on velocity.
Opportunity Cost of Slow Velocity: While harder to quantify, this is often the most significant factor. It represents the lost revenue or strategic advantage from features that are delayed due to testing friction.
The journey from the exponential pain of traditional microservices testing to a new paradigm of request-level isolation, AI-powered validation, and platform-driven workflows is complete. The choice is no longer a trade-off between speed and quality; modern testing platforms are designed to deliver both. The million-dollar problem is real, and the solution is here. It is time to evaluate your testing strategy and calculate your own cost of delay.
Get the latest updates from Signadot

