Staging was meant to ensure quality, but for many teams it has become the biggest blocker: fragile, shared, and constantly breaking under parallel work. Now that AI coding agents generate far more code, that single shared environment is the main thing slowing teams down. Here is why it no longer scales, and how per-pull-request sandboxes fix it for developers and agents alike.
A few weeks ago, I had a conversation that I can’t stop thinking about. I was talking to a Director of Engineering who leads a 100-person team, and I asked him about his biggest development bottleneck. I expected to hear the usual suspects: CI/CD performance, code review cycles, or maybe deployment complexity.
His answer was immediate and emphatic: “It’s the staging environment”.
He went on to describe a scenario that is painfully familiar to anyone who has worked in a scaling engineering organization. “We have one staging environment,” he said. “At any given time, 3-4 teams are trying to push their changes in for testing. It’s constantly breaking, and we spend hours trying to figure out whose change caused the issue”.
I summed it up: “So it’s a race to merge, followed by a blame game?”.
“Exactly,” he confirmed. “Devs get frustrated. QA gets blocked. We either delay releases or ship things with less confidence because we couldn’t get a clean testing window”.
This story was so resonant that I shared it on LinkedIn. The reaction was overwhelming, sparking a massive discussion with hundreds of comments from engineers, architects, and leaders across the industry. It was clear this wasn’t an isolated problem; it’s a classic scaling challenge that I’ve seen grind velocity to a halt at countless companies. The traditional model of a single, shared, long-lived staging environment simply breaks down under the pressure of multiple teams moving in parallel. It creates a zero-sum game where one team’s progress often comes at the expense of another’s. The very environment meant to ensure quality becomes the biggest single point of failure and contention.
But what if we could fundamentally change the game?
High-performing teams deploy code 973 times more often than low performers, so the pressure on a single shared environment is relentless. (If you are still standing up the environment itself, start with our guide to Kubernetes staging environments.) Before teams rethink the model, they usually try to manage that pressure. None of these workarounds holds up as the team grows:
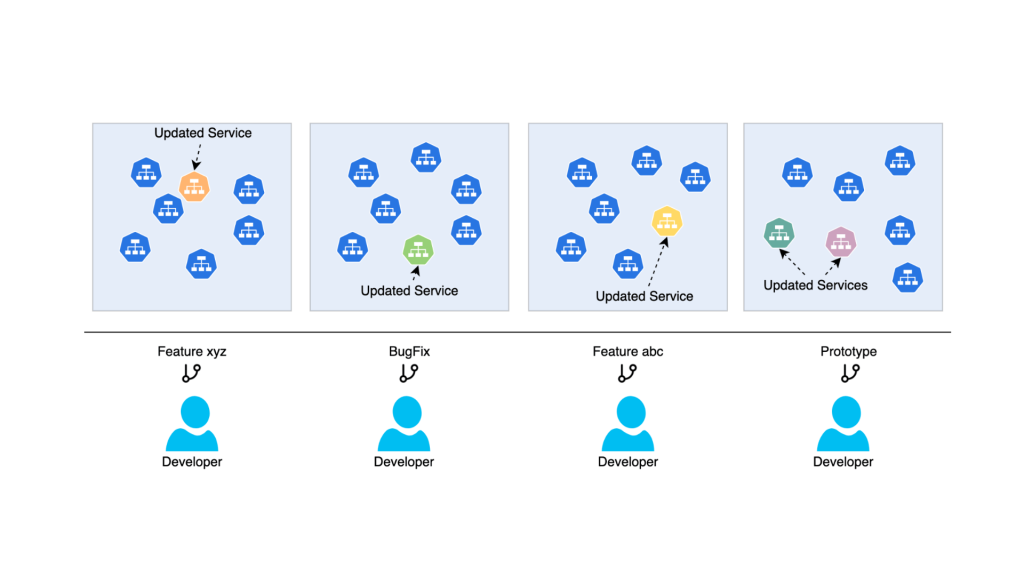
The irony is that each of these, in trying to fix staging, creates a new problem. What teams need is not more environments. It is a smarter way to use the one they have.
The old model is built on scarcity, one environment that everyone must share and fight over. The new model is one of abundance. The solution is to give every developer a personal, ephemeral “sandbox” for their feature within the same shared environment.
This isn’t about duplicating your entire stack a hundred times over. That would be a cost and complexity nightmare, a valid concern many people raised in the discussion. Instead, the modern approach is far more elegant and efficient. Through smart request routing, we can isolate each developer’s changes from everyone else’s, even though they share the same underlying infrastructure.
Imagine Developer A is working on a feature. They can deploy their pull request into a personal sandbox. When they send a test request to the staging cluster with a specific header, the request is intelligently routed to their modified service. For all other dependencies, the request is routed to the stable, baseline services running in the main staging environment. This means Dev A can test their PR without ever being affected by Dev B’s work, and vice-versa.
The analogy to source control is almost perfect. The main staging environment is your trunk or main branch, the stable baseline. Each developer’s sandbox is like a feature branch, isolated and independent until you’re ready to merge.
The results we’re seeing from this shift are profound:
Testing Contention: Eliminated.
Environment-Related Release Delays: Down by over 90%.
Time Spent Debugging “Who Broke Staging”: Near zero.
The Director’s follow-up question perfectly captured the promise of this new model: “You mean my teams can test in parallel without stepping on each other’s toes?”. Yes. That’s the power of modern development infrastructure.
The vibrant online discussion that followed my post surfaced a number of valid and challenging questions. For this approach to be viable, it has to hold up to real-world scrutiny. Let’s tackle the most common discussion topics head-on.
This was, by far, the most critical counterpoint. One commenter articulated the problem perfectly: even with temporary environments, you cannot spin up a temporary database with large test datasets for every developer, so “all these environments end up sharing the same database”. This becomes a huge issue, “especially when a developer needs to make schema changes that are not backward compatible”.
This is absolutely correct. The data layer is a crucial piece of the puzzle. The solution requires a multi-faceted approach:
For Most Cases, Share the Database: For the majority of changes that don’t involve schema modifications, sandboxes can share the main staging database. This works well as long as teams follow best practices, such as not mutating data they didn’t create. The rich, representative data in a shared staging database is incredibly valuable for testing.
For Schema Changes, Isolate the Database: For cases where full data isolation is required, you must spin up a temporary database with the sandbox. This could be a containerized DB, a separate schema, or a branch if you’re using a modern database that supports it. This temporary DB can be seeded with a snapshot of production data to ensure realistic testing.
Automate the Cleanup: A valid concern was the cost and complexity of managing these temporary resources, with developers potentially leaving them running after a merge. The key is automation. These temporary resources must be linked to the lifecycle of the sandbox itself. When a sandbox is deleted (either automatically on PR merge, via a TTL, or manually), the associated temporary database is automatically cleaned up with it.
Many commenters worried about the infrastructure costs and setup complexity of ephemeral environments. One was blunt, suggesting “it increases costs a gazillion times”.
This is a misconception rooted in the traditional approach to ephemeral environments, where you duplicate the entire stack. The sandbox model I’m proposing is fundamentally different and far more cost-efficient. You are not cloning 15+ services for every developer. You are only spinning up pods for the 1-2 services that are actually changing in a given PR. The rest of the stack is shared.
The cost of running a few extra pods in your Kubernetes cluster is minimal compared to the staggering cost of developer downtime, blocked QA teams, delayed releases, and hours spent in “blame game” war rooms. The long-term savings in developer productivity far outweigh the infrastructure costs.
As for complexity, building this from scratch is indeed a significant undertaking. You’d need to manage shadow deployments, integrate with a service mesh for routing, handle header propagation via OpenTelemetry, and build a system for spinning up temporary resources. This is precisely why we built Signadot, to provide this capability as a managed platform so teams can focus on their own products.
Several people argued that by testing in isolation, you miss the very integration issues that staging is meant to catch. They suggested this might “shift the integration pain to the right” and that “If the changes are still separated, you don’t know if they work together when you push them to production”.
This is a critical point, and it highlights a misunderstanding. This approach does not eliminate the staging environment or the need for integration testing. It supercharges it.
The goal is to “shift left”, to find and fix as many bugs as possible before code is merged into the main branch. By performing integration testing against a stable baseline in a pre-merge sandbox, you gain a high degree of confidence. Post-merge testing on the main staging environment becomes much shorter and smoother because you’ve already ironed out the majority of issues.
Furthermore, what if a single feature requires changes across multiple PRs from different teams? Sandboxes can be grouped together, allowing you to test a collection of interdependent PRs as a single, cohesive feature before any of them are merged. You’re still performing integration testing, but you’re doing it earlier, faster, and in a controlled, isolated manner.
A number of comments suggested this was a process or architecture problem, not an environment problem. Suggestions included Trunk-Based Development (TBD), better CI pipelines, or simply having developers run everything on their local machines.
While all these practices have value, they don’t fully solve this specific problem at scale:
Local Development: Running a complex, distributed system with 20+ microservices, databases, message queues, and cloud resources locally is often impossible. As your system grows, local development can’t replicate the production environment’s complexity, leading to the dreaded “it works on my machine” scenario.
Trunk-Based Development: TBD is a fantastic practice, but it’s orthogonal to the issue of testing. You still need a way to validate changes before they land on the trunk, especially when those changes have complex interactions with other services. This sandbox approach provides a powerful way to do pre-merge validation, which perfectly complements TBD.
Fixing the Architecture: While better architecture and loose coupling are always good goals, even well-architected systems have dependencies. The need to test how services interact doesn’t disappear. The bottleneck isn’t just about code; it’s about providing a realistic, scalable environment for integration testing.
This is not theoretical. The companies that hit microservices scale first all landed on the same answer: isolate the change, not the whole environment.
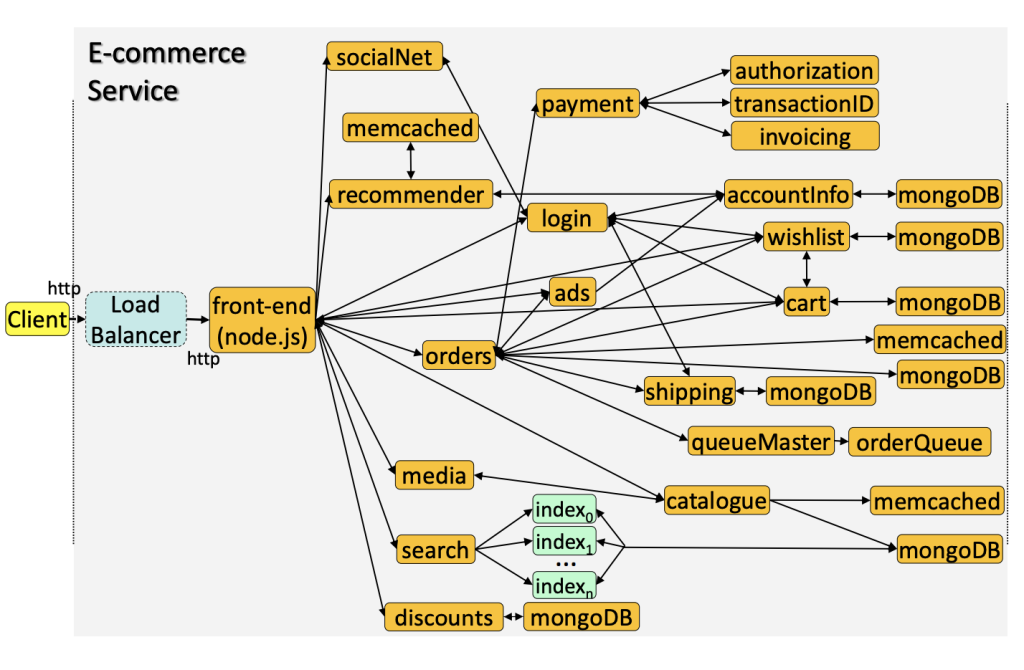
The instinct to “just run everything locally” does not scale either. As distributed-systems engineer Cindy Sridharan observed, “trying to spin up the full stack on developer laptops is fundamentally the wrong mindset to begin with.” Modern systems are too interconnected: a failure in one service, say payments, often surfaces as a bug in another, like orders, which is what makes interdependencies the hard part of testing.
The payoff is measurable. AWS documented a 15.9% year-over-year cost reduction and 433% three-year ROI from developer-experience improvements, and Gartner expects 80% of large engineering organizations to run platform-engineering teams by 2027, up from 45% in 2022. What once took a dedicated platform team at Uber or Lyft to build is now available off the shelf, so teams of any size can adopt the same request-isolation model today.
Since I first wrote this, the ground has shifted. A large and growing share of code is now written by AI coding agents like Claude Code, Codex, and Cursor. A single engineer can open more pull requests in a day than a small team used to open in a week. The part we spent a decade trying to speed up, writing the code, is no longer the thing holding us back.
The constraint has moved downstream, to validation. When an agent produces ten changes in the time it used to take to hand-write one, every one of those changes still has to be proven correct against the rest of the system. For a cloud-native application that means running it in a realistic environment with its real dependencies, and that is exactly where the old staging model buckles. A laptop cannot hold the full stack, so local testing stays low fidelity. Shared staging can hold it, but now it has even more changes queued for the same single lane. The faster agents write, the longer the line for staging gets.
This is why the sandbox model matters more now than when I first described it. Agents do their best work when they can close the loop themselves: make a change, test it against real dependencies, read the result, and try again, without waiting on a person or a shared environment to free up. A per-pull-request sandbox gives them exactly that, an environment that is quick and cheap to create but still high fidelity because it runs against the real baseline. The same request-level isolation that lets a hundred developers test in parallel lets a fleet of agents work at once without stepping on each other.
An environment on its own is only half the answer. To let agent-written code merge with confidence, you need a validation layer sitting on top of it. At Signadot that layer is Sandboxes for the environment, plus SmartTests, Jobs, and Plans for the checks that run inside it. SmartTests catch behavioral regressions by comparing the baseline against the change, Jobs run the test suites you already trust against the sandbox, and Plans tie them into one repeatable workflow an agent can run and act on. Together they take a change all the way from generated to verified. I wrote up the longer version of this argument in validating AI-generated code on Kubernetes.
None of this replaces the staging environment or the integration testing it stands for. It does what shifting left always promised: it moves validation earlier, makes it cheap enough to run on every change, and keeps it high fidelity. For where sandboxes fit in the full lifecycle, see our complete guide to microservices testing. That was worth doing when humans wrote the code. Now that agents write most of it, it is the difference between shipping faster and drowning in unverified pull requests.
Ultimately, solving the staging bottleneck is about more than just tools; it’s a cultural shift. It’s about moving from a rigid, sequential process to a flexible, parallel one. It requires adopting a platform engineering mindset, where the platform team provides self-service tools that empower feature teams to move faster.
Instead of a centralized gatekeeper (the staging environment), you create an ecosystem where every developer and every PR gets an isolated slice of the testing workflow, on-demand. The blame game disappears, confidence goes up, and teams can finally realize the core promise of microservices: the ability to develop, test, and ship smaller code changes to production independently and rapidly.
The journey from a congested, single-lane road to a multi-lane superhighway for development is challenging, but the destination, faster releases, higher quality, and happier developers, is more than worth the effort.
How does your team manage the staging environment bottleneck? I’m keen to hear your strategies.
Get the latest updates from Signadot

