There are a number of solutions to flaky tests, only some of which involve preventing inconsistent test results. Some make changes in testing processes, others in testing environments, and some even require changing the way you think about tests.
_There are various solutions to flaky tests, only some of which involve preventing inconsistent test results._
Flaky tests, a common challenge in software development and platform engineering, are often seen as a nuisance, but their impact on developer velocity can be quite significant. In my previous article, I explained what causes flaky tests and how they damage your developer velocity. In this article, I’ll look into how to solve the problem of flaky tests.
There are a number of solutions to flaky tests, only some of which involve preventing inconsistent test results. Some make changes in testing processes, others in testing environments, and some even require changing the way you think about tests.
What’s the best way to fix flaky tests? The standard advice is: fix them. In my previous article, I mentioned a Reddit user asking for advice about handling flaky tests.
User u/abluecolor on Reddit advises:
stop writing more tests until you get a handle on this. You may need to do some degree of maintenance on ALL of them. You need to pick a starting point, do a deep dive, isolate the root cause of flakiness, and will likely need to do some work on the process, environment and code side to rectify it. There are innumerable possibilities, and not enough details to be all that valuable in answering at this point.
And really, if you’re on a small-ish team, this is good advice! If you have just a few hundred tests, it should be possible to isolate the tests that most frequently fail and work a spike to resolve all of them. In general, this approach may not scale: the rate new tests are created will generally outpace your ability to research every flaky test.
On the Slack engineering blog, Arpita Patel provides a great narrative about focusing and trying to resolve flaky tests at scale. At the scale of Slack’s automated mobile testing, there was no chance of resolving all flaky tests individually:
“There are 16,000+ automated tests on Android and 11,000+ automated tests on iOS with the testing pyramid consisting of E2E, functional, and unit tests.”
They started by quantifying the negative impact from flaky tests and giving the developer experience (DevX) team the bandwidth to work up a large-scale solution. The resulting system set thresholds for automatically suppressing flaky tests.
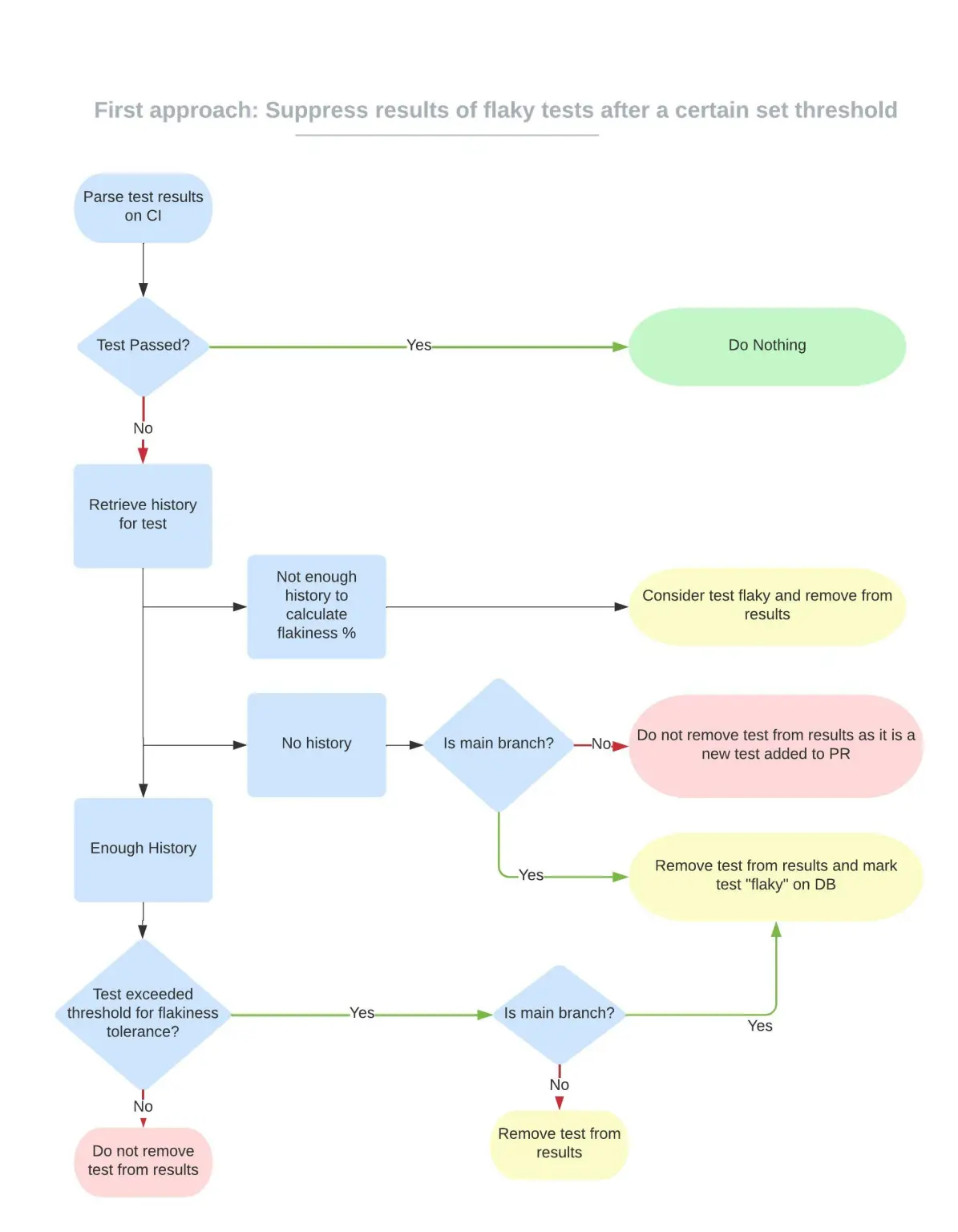
Source: https://slack.engineering/handling-flaky-tests-at-scale-auto-detection-suppression/
This approach had two major drawbacks:
This approach won’t work for all teams. A “quick and dirty” implementation without rate monitoring would inevitably suppress useful tests, and a full-featured solution isn’t available as a product yet.
One possible solution to timeout-based failures is to either remove timeout tests or change the test expectations. Several commenters on the Reddit thread suggested resetting all timeouts to 30 seconds, so only massively slow responses would trigger a failure. But Reddit user u/Gastr1c gives some level-headed advice that this isn’t a good idea:
I dislike blindly coding implicit timeouts to the entire suite. Red alert if you have to set an enormous 30-second timeout to the entire suite. You’re just masking real issues. Instead, write your tests to explicitly wait for X to complete, whether that’s UI elements to be visible and/or network calls, and set reasonable performance timeouts for those.
Work with the team to understand the performance issues. Perhaps they’re legitimate app performance issues? An API or backend doodad changes and negatively affects the frontend? Don’t simply assume it’s “standard flake.”
While there may be some validity to moving below-expectation responses and failing tests only in extreme situations, doing this everywhere with a blanket value starts to beg the question: Why have tests in the first place? If a service that used to respond in 10ms starts taking 7,000ms, it shouldn’t go out to production. Lowering your expectations of testing will mean more faulty code released to production.
What if you allow very slow responses in the testing phase, since the slowdowns may just be artifacts of the testing environment, and implement canary tests that roll back if response times increase? Along with the technical challenges of implementing this strategy, you’re really just kicking the can down the road: now regressions will take longer to detect, resulting in more costly process delays when deploying code is found faulty and returned back to the development stage. For more on why this is a problem, see Arjun’s Iyer’s article Why Testing Must Shift Left for Microservices to learn how the software dev lifecycle can be broken by too many feedback loops that take too long.
u/Gastr1c, gives a great segueway into rethinking your testing environment:
If you’re running tests in a shared live deployment, change to a deployment that is ONLY used for test automation to remove the chance others are negatively impacting the system. Spin up a new, fresh, unique and dedicated deployment for each specific instance of CI. You’re not going to be able to parallelize and run concurrent CI workflows without it, or tests will be stepping all over each other.
Measuring response times results in non-deterministic behavior. If you accept that it’s not a good idea to remove your high response time expectations, you should be motivated to control everything possible about the testing environment. If you elect to switch away from a shared testing environment to an environment for test automation alone, you’d spin up new environments for each team’s test runs to prevent simultaneous testing from causing slowdowns.
I wouldn’t say that this strategy is universally useful. There are three main drawbacks to the strategy of “stand up an environment for each run of the test suite”:
I agree that you need to think about your testing environment. Saying, “sometimes services that respond in 7ms take 1000x longer on the test envrionment” points to the test environment as the real source of the problem. My disagreement is whether using one-off environments is the answer.
How can large teams have a shared testing environment that runs about as well as production, is available to all teams to run tests anytime and doesn’t get blocked for one team when another is using it? Consider request isolation.
For about a year, I’ve been interested in request isolation as a new way to test in a high-accuracy environment.
In a modern Kubernetes environment, you can share a cluster for testing without forcing the test versions of your services to interact or hog resources. The goal is request-level isolation, which relies on two standard capabilities in the modern microservices stack: generalized context propagation and request routing. Tools like OpenTelemetry facilitate context propagation, while service meshes and Kubernetes networking sidecars enable request routing.
In this model, when a developer tests a new version of a microservice, service dependencies are satisfied from a shared pool of services running the latest stable version, known as the baseline. This baseline is continually updated via a CI/CD process, ensuring testing against up-to-date dependencies.
Even if your test services are being deployed to a cluster with a service mesh configuration that ensures only marked requests go to the test service, you’ll still have some limitations. If your testing process involves stateful requests, you’ll need to do some work to clean up from each test run. As multiple test runs update your shared datastore, you’ll find unexpected behavior if you’re measuring things like the total number of records. All of this is obviated by the ephemeral test solution mentioned previously, but the benefits of a large, accurate shared testing cluster seem worth the cost of adding a cleanup step to the end of each test run, and possibly rewriting a few tests that repeatedly check the data-store’s state.
This method of isolation ensures that changes made by one developer are kept separate from another, thus preventing cross-dependency and unpredictable staging environments . This leads to faster, scalable testing, high-fidelity environments for more confident development, and reduced costs by eliminating the need to maintain extensive namespaces and clusters.
Flaky tests are a pervasive issue in software development, particularly as teams scale up and systems become more complex. They not only hinder the efficiency of the development process, they also impact developer morale and trust in the testing system. While there’s no one-size-fits-all solution, several strategies can mitigate the impact of flaky tests. These include revising the testing process, adjusting test expectations and rethinking the test environment.
A promising solution for large teams working in complex environments is request isolation, particularly in Kubernetes environments. Request-level isolation allows shared use of a testing cluster without the drawbacks of cross-dependency and resource interference. By isolating changes and testing them against a continually updated baseline of stable versions, this approach offers a high-fidelity testing environment that is both scalable and efficient.
If you’d like to talk more about the art of developer experience and reliable, high-fidelity testing, join the Signadot Slack community to talk to others trying to increase developer velocity.
Get the latest updates from Signadot

