This article highlights how centralized testing is hindering developer velocity in microservices architecture. While development is decentralized, testing remains centralized, causing delays. The proliferation of environments worsens the issue, leading to testing cycle delays and hindering the release process. The scenario illustrates these challenges and emphasizes the need for decentralized testing to enable smoother deployment experiences.
Originally from TheNewStack
Here’s why testing has become a choke point for developer velocity.
The beauty of a microservices architecture is distribution. No single person needs to manage, monitor or write every part of a system. When there’s a problem, it should be isolated to a few services so that you don’t need to go to the same senior engineers every time. Instead, the experts from those services’ respective teams are the only ones who need to understand the problem. But when it comes to testing releases, things have gotten oddly centralized.
Integration testing is a highly critical stage for microservices since this is where you often find out if your code really works. While unit testing and some testing with mocks and stubs can happen before integration testing, the integration phase is where most real testing happens. The trouble is that this testing can’t happen, or can’t happen very realistically, until rather late in the process. Worse, it’s centralized, with a single team often responsible for managing a test or staging environment, and has a slow feedback loop, where problems are documented during integration and then sent back up to the development team that created the features to fix.
We need to decentralize testing the same way we’ve decentralized development and many other components of production operations. We need to put more testing in the hands of developers earlier (a “shift left”) so that they can find integration problems earlier — before their code can impact other teams.
Paradoxically, centralization of testing has led to a larger number of environments in flight. This pattern seems to occur because, since testing is centralized and relatively slow, teams try to add environments beforehand to get an idea of whether code will work in staging and test environments.
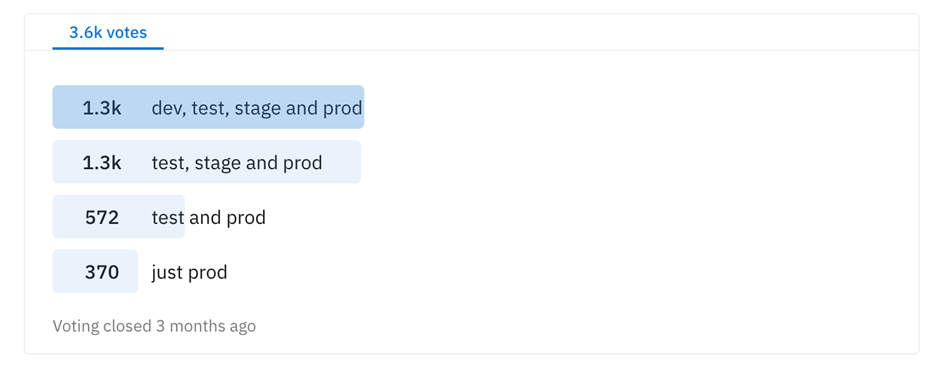
How many environments are enough? Moreover, why isn’t this something we can all agree on? When I started out as a developer, I had a quality assurance (QA) environment and a production environment. Staging was in between, but it was unused and didn’t reflect production very accurately. Later, I identified that the initial run of code on my laptop was yet another environment where it was running. So I had dev, QA and prod. And that was enough! But look at a recent informal poll of DevOps engineers asking what environments they have: More than a third use dev, test, staging and production environments.
Modern DevOps and CI practices, when applied to microservices and modern hosting architecture, have brought us back to deployments that look more like waterfalls — cumbersome practices that often rely on human practices to get code out the door. One contributing factor to this antipattern is the large number of disparate environments that QA and operations must wrangle.
We begin our scene in a Monday video call with an engineering team. They’re building a cloud native application, and the small teams (A, B and C) meet up on Monday mornings to define what features they’ll add to their microservices. Each team manages between one and three microservices, and they know their codebase well and how to add features quickly. Team A agrees on what they’ll work on and targets a release date of next Monday, in seven days. They’re not going to make it, and environments will be the culprit. Let’s talk about why.
Even though Team A knows their microservice’s code like the back of their collective hand, they can’t run the service’s code in isolation to much benefit. It might help to do it as they’re writing the code, but its dependence on services from Team B is significant enough that it won’t tell you much. So teams A, B and C all use a shared environment called Dev to deploy and test their code. All this is very easy, very convenient, and code written Monday afternoon can be run on the shared cluster that same day. The great benefit of this Dev cluster is it’s up to date: the most recent version of all three team’s services is on there.
On this day, though, something’s not working right, and Team A’s service is failing each time it interacts with Team B’s service. No bother, Team A can reach out on Slack and figure it out.
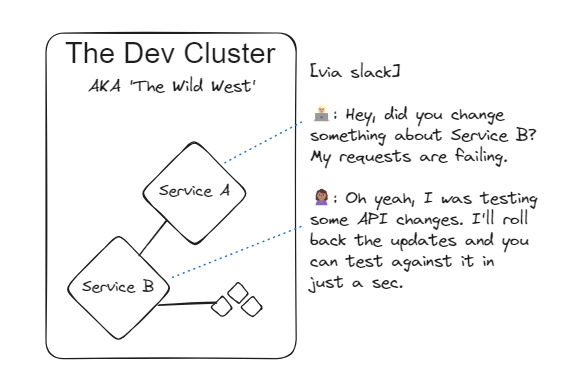
The great thing about the Dev cluster is that you can deploy whatever you want, but when Team B was experimenting late last week, they left Service B in a state where it won’t handle requests as designed. No worries, they do a rollback, and by Tuesday morning everyone is ready to test.
By Tuesday afternoon, things look good, so they’re ready to ship to the QA environment. This is a necessary step since the QA and operations engineers maintain a bunch of dependencies on this cluster that aren’t available on Dev. Stuff like third-party payment providers are on QA with dummy credentials and more “production-like” versions of data stores are there too. Once Team A packages its updates and writes up a pull request (PR), it’s ready to go to the next team.
The QA team looks for merges to a main branch to know when it’s time to deploy changes to the QA cluster and starts testing from there. This feature is a day behind, but by Wednesday morning they’re ready to get started. Typically the QA team doesn’t test individual microservices, preferring to grab all updates and test the system end-to-end (E2E). This is a great help since it means they know whether updates will really work on the complete system. But it also ends up causing delays.
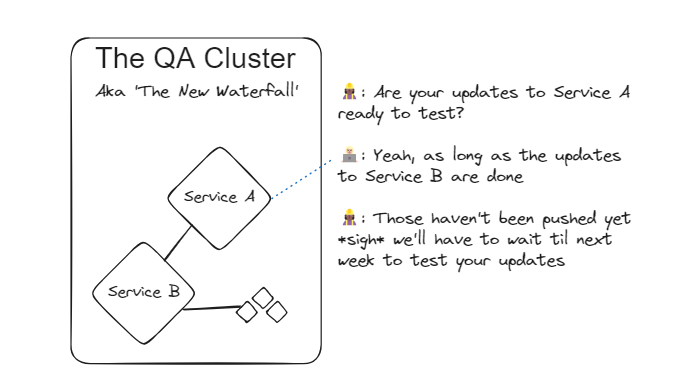
It turns out that the updates rely on Team B’s new features from last week, and for various reasons, they haven’t been merged to main yet. Now they’re really seeing delays. It takes a while to diagnose this problem, and Team A doesn’t realize the issue is syncing QA up with Team B’s changes until Thursday morning. They ask Team B to rush their merge to main, but this is a human process and takes time, so it’s not until Friday morning that everything is merged and ready to go back to QA.
By this time, they’ve already blown their deadline, but things are about to go from bad to worse: QA teams vary their testing cadence, but they generally don’t work completely on demand. This means they’ve missed the testing runs for the week and have to wait until Monday. Team A can get some automated test feedback from Selenium or Playwright (assuming they are running automated E2E tests against Staging). But these tests don’t cover every case, so Team A has to decide if it’s worth waiting for QA’s feedback or whether they should just plow ahead, fixing what the automated tests found to prepare for more manual testing.
Keep in mind that they’re finding out now, early in the second week of the process, whether there are real integration problems with the features for Service A. It’s likely that QA will find real problems. Once QA does find problems, they have to document the issues and include replication steps. They’re not the original feature developed, so this documentation may or may not point those devs back to the exact cause of the problem.
Devs work the problems discovered out of a bug queue, and unless they’re really prepared to push this feature, it’s likely that Team A won’t work this bug right away. At this point, the one-week timeline has stretched to two weeks or more.
It’s been two and a half weeks, and they’re ready to release. Of course, this is a major feature, so they would like to have product managers and others sign off on the changes. Notably, this wasn’t part of the initial one-week estimate, but it still counts.
Either by using feature flags or a third pre-prod environment, changes QA passes are released for internal stakeholders to review. While this wasn’t part of the initial timeline, it affects the timeline when the feature doesn’t perfectly match expectations. No one at the QA or operations level can fix the issue, so the feature goes all the way back to Team A. Worse, since Team B updated its service in the intervening two weeks, the same delays will happen as they negotiate over the Dev environment, wait for things to sync up for the QA environment and on and on.
Microservices and their interdependence can cause real problems for a smooth, high-velocity development and deployment process. The timeline described above isn’t exceptional, and without anyone working out-of-band on a critical, priority 0 (P0) issue, the time to release features can stretch from weeks to months. Since the process involves multiple steps of dev and QA having to communicate about issues, the process is less automated and more manual than ideal. Is this a nine-month waterfall? No, but to remain competitive, we need to seek the best developer velocity possible, and this ain’t it.
The result will be commits that are more and more batched with other teams’ work. This ensures that testing happening on QA involves as many updates as possible. This is good for high-accuracy testing but bad for developer velocity.
Along with the general friction of out-of-band problems and a slow process, a great deal of what’s described above involves direct human communication to diagnose and fix problems. QA teams have to write up bugs and replication steps, dev teams have to repeatedly describe new commits for QA, etc. This human communication adds greatly to the friction and the need for synchronous work. Imagine the scenario above with a distributed team working in Europe, North America and Asia. The same two-week process could take a month.
This is how centralization of the testing process leads to slow ticket-based communication of problems, and the relatively high-velocity async process of product development stumbles as multiple teams try to synchronize for testing.
In my next article in this series, I’ll share ways to improve developer velocity by decentralizing testing.
On a recent Reddit thread, user u/ellensen describes a setup that’s consistent with the scenario above:
Our DEV environment is a sandbox environment without automatic deployment pipelines where our applications are configured using the same Terraform that our automated environments [use], only applied manually by developers from their laptops. This is like a sandbox environment without any expected stability to do really what you want with applications, and other developers should not expect even the applications to be running or like they left the application last time.
This is an example of the basic balance of freedom at the expense of stability: the Dev environment lets you do whatever you want and manually apply updates. On the other hand, developers can’t expect that things will be stable when they come back to this environment.
Ellensen goes on to describe how TEST and STAGE are quite similar, with developers often taking slightly different paths to make sure their code is working before QA. But then come the frustrations:
The whole system is stable and working quite nicely; because everything is maintained by Terraform, it’s not very heavy to maintain, […] but when you do harder refactoring, where you need to move big components around, you get to practice deployment to dev, test and stage before going into production. And after three test deployments, you can be quite certain that everything is working fine, we have very seldom, if ever, bad deployments in prod.
While this process doesn’t tend to release bad code to production; it is slow, and any problem found late in the release process can require some out-of-band effort to fix. Further, major updates to services must be propagated into a large number of environments upstream.
If you’d like to join a community that’s enabling developer experience (DevEx) at a high level and talk about strategies for a smooth testing and deployment experience, join the Signadot Slack community to connect with others trying to increase developer velocity.
Get the latest updates from Signadot

