Testing microservices is often riddled with challenges—especially when trying to isolate issues in APIs without relying solely on end-to-end testing. While tools like Pactflow and Diffy aim to address these hurdles, they often demand significant setup and still fall short in identifying certain nuances, like non-deterministic or context-specific differences. This article introduces an innovative approach: using relevance-weighted models for REST API message diffs. By incorporating probabilistic modeling and context-aware analysis, this method filters out noise, adapts to system changes, and simplifies setup, offering a smarter, more scalable way to debug and maintain microservices.
Image from Unsplash by Ales Krivec.
There are a myriad of tools such as Pactflow and diffy which address the problem of testing micro service APIs in a piecewise fashion, as opposed to end to end testing. The potential advantages of testing piecewise are well-known: easier debugging, less maintenance cost due to the locality of scope of the tests, more efficient test executions, etc. However, many challenges remain in large part due to the effort involved in setting up and deploying the requisite tools, especially in the face of changes to the system under test.
In this article, we present a different approach which uses a model of REST API messages which tracks the reference implementation over time. With this model, a relevance score for individual diff operations allows to distinguish differences between candidate and reference which also occur naturally between different runs in the reference.
Such differences tend not to be schema changes or bugs. However, they are in general difficult to identify. They may be differences in timestamps, differences between opaque identifiers used in each run, differences of values of non-deterministic enums reflecting system state, or take any number of forms. Existing tools such as diffy require extensive setup and can not reliably identify certain kinds of differences. By contrast, computing relevance as a score has a one time, cluster-wide setup and is able to identify a more precise set of relevant differences automatically.
The diagram below shows the flow of the testing system in which our relevancy-weighted differences are calculated. The test runner and reference and candidate systems capture REST HTTP requests. Every time a difference test is run, the captures from the reference system are modeled as described below. The reference and candidate systems are implemented using Signadot sandboxes.

The system for calculating differences operates on captures, which are representations of HTTP requests and responses sent for capture. Captures are sent for reference and candidate requests and responses, and the system models reference captures. Below is the data structure representing captures in Go.
A key property of captures is that they are generic, allowing any structure to be modeled, as indicated by the Go type associated with message bodies.
Captures are modeled with a group of structures each of which follows the pattern below.
Following JSON syntax, there are structures for Booleans, numbers, strings, arrays and objects.
For Booleans, the models just track the frequency of true values. Strings are hashed into buckets, each of which holds up to 32 of the most frequently observed examples. This gives us a fixed maximum size with plenty of space for enums or commonly occurring values.
Numbers are modeled as either 64 bit floating points or integers. Whenever an observation is exactly an integer, it is recorded with the integer model. Otherwise, it is recorded into the floating point model.
The frequency of integers vs floating points is tracked. Floating point models are modeled by an incremental/online normal distribution (with mean and variance). Integer models model the sign as a Boolean and the frequency of every number in [0..16) associated with each contiguous 4 bit segment of its binary representation.
While the types above are relatively straightforward, a model must allow for any mix of schema. This is necessary because JSON arrays allow any mix of schema, such as in the example below. However, more importantly, our models must be able to record observations of different types to accommodate changes in the data being modeled over time.
We accomplish this using set of probabilistic grammars each associated with a context.
The probabilistic grammars are simply weighted JSON grammar productions for JSON values. Following the example above, there are 2 arrays, 1 null, 1 number (11), 3 strings ({"a", "b", "c"}) , 1 Boolean, and 1 object, for a total of 9 productions of JSON values.
The shape model is just an association of the productions with weights, for example
Arrays and objects are recursive productions, and we use context as described below for recursion. However, the shape of arrays and objects is richer than just a weight. For arrays, we use an integer model for its length and for objects we use a simple bigram model for sequences of fields.
Shape models are not sufficiently rich for most applications, because all the different structures of data are represented in a single flat entity; one cannot distinguish substructures whereas applications almost always do.
To accommodate this need, we model full JSON documents as a set of shapes, each of which is associated with 2 hops of the parent relation in the JSON syntax tree, where a parent can either be a field name in an object or a JSON array. In the following, these 2 JSON syntax parents of each node provide its *context.*
For example, given the JSON
the value at the field field1Inner1 is modeled with a shape associated with the parents.field1.field1Inner1. Since it only appears as Boolean, the associated shape would have a Boolean model associated with it.
Similarly, the values at the paths /field2/0/item0Field1 and /field2/1/item0Field1 would both have the context .[].item0Field1 ([]meaning “in an array”).
Each context which appears in any node in the JSON syntax tree in any observation becomes part of the model, and has an associated shape.
In the event the context contains object or array productions, this provides a means to look up another context. For example, in context .field1.fieldInner3 there is an array production in the example. Elements of that array have context fieldInner3.[] , and the context has shifted. This ability to shift the context is useful for using the model to generate JSONs and to recursively evaluate probabilities.
By modeling contexts in this way we can associate any JSON node with a model while controlling the total number of contexts that we represent.
A very nice result of this is that we can throw any JSONs from any different number of places at the same model and still have a good chance of getting accurate models, provided the 2-parent context disambiguates cases across the different sources of JSONs.
Request and response formats are typically associated with hosts, but they are often variable across different request paths, such as /products/{productID}and /customers/{customerID}. In REST parlance, these paths take parameters at fixed places in the path.
Often, a set of related endpoints share a lot of structure, and unrelated ones do not. For example
would often return structures representing customers, perhaps inside of an array in the first call. Whereas
would often return different structures (unless the customer is the product :).
However, our models work solely off of observed captures and so we have no way of knowing which path components are parameters.
As a result, in our system we simply take into account the length of the path parts and the http method. This might lead to some inaccuracy in the models, however, given the way the JSONs are modeled by always tracking 2 parents of context, such inaccuracy can be mitigated substantially or even entirely eliminated in many instances.
Given a reference capture and a candidate capture, we calculate the difference between the two using a standard jsondifflibrary. This inevitably contains many innocuous differences, such as timestamps and opaque identifiers. Some differences may be difficult to discern, for example status information about underlying state may differ due to non-determinism of the underlying state. Perhaps such differences point to a bug, or improved performance, or perhaps they are just noise.
A diff produced by jsondiff can be an addition, a removal, or a replacement. Each operation is associated with a path in the reference capture, and this is the most precise path that is shared between the reference and the candidate.
Given such a path, we lookup the 2-parent context in the json model and ask for the probability of the value that is found in the candidate at that location according to the reference model. Let this value be p in what follows.
It should be easy to see that if the value in the candidate is very likely to occur in the baseline, then the difference in the candidate is noisy, or irrelevant. It should also be easy to see that if the model itself has very little predictive power, because it is very entropic, then the candidate value is noisy, and no particular value is probable in the reference model.
However, entropy is a difficult value to work with because it has no real bounds. Booleans have a maximal entropy of 1 bit, whereas 64 bit integers have 64 bits of entropy possible.
Additionally the models themselves have a maximal entropy which is different than the value being modelled. Moreover, the maximal entropy may be a function of the total number of observations.
For these reasons, we incorporate the idea of relative entropy, which is the ratio between the entropy of a model and its maximal entropy. In the following, let this value be e
Relevance is a value in the range [0..1]we provide for every diff operation between a reference and candidate capture. To calculate it, we calculate a noise value for the operation, which is also in the range [0..1] , and then, the relevance is
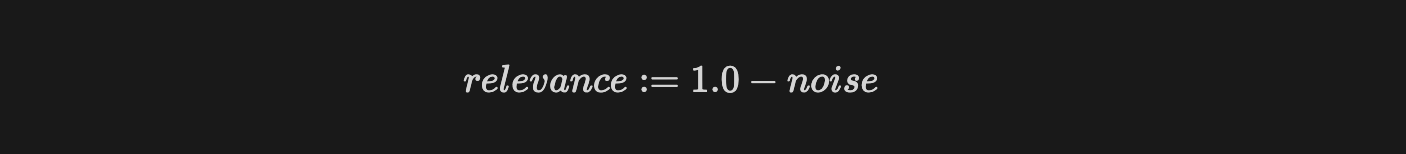
The noise, in turn, is a function of the values p and e mentioned above, respectively, the probability of the candidate value occuring in the reference model and the relative entropy of the reference model for this value.
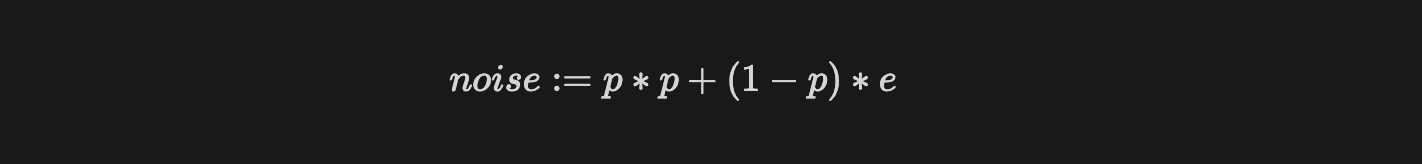
When p is high, the entropy must be low and the term p * p dominates. When the entropy is high, p must be low and the term (1-p)*e dominates.
The expected form and values of reference captures can change over time as it is developed and so the associated models should be adaptive to change. When an observation is recorded by a model, one can think of it having weight 1. As the model incorporates more observations, the impact of recent observations diminishes. To keep models reactive to change, one could imagine recording observations with increased weight over time. We can achieve the same effect while avoiding overflow by scaling the models by some value less than 1. When the model is scaled by 0.5, it is as if subsequent observations are recorded twice.
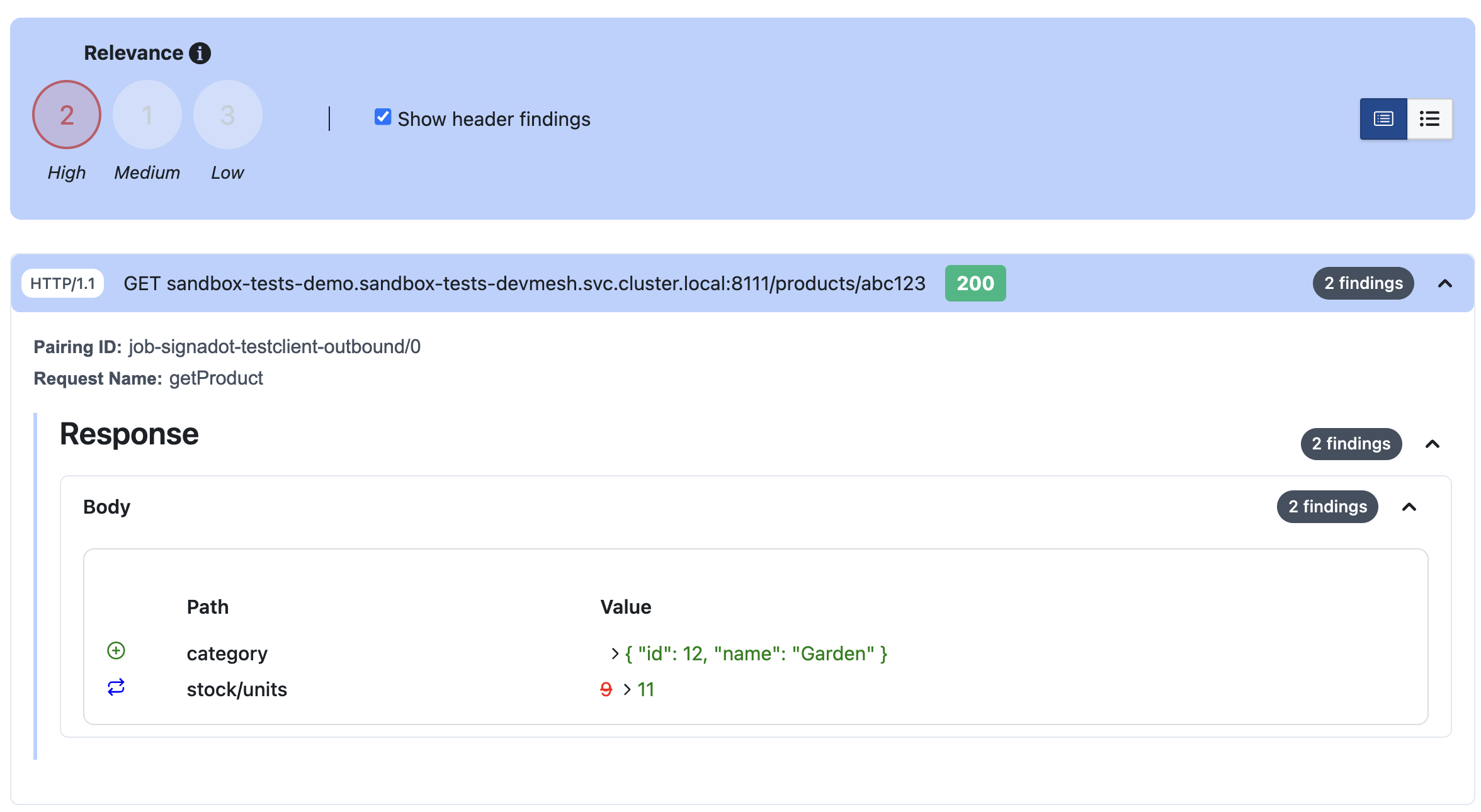
With relevancy weights in place for captures, it is easy to see how code changes effect on-the-wire requests and responses. In the screenshot below, the schema of the category field of a response changed and the value of stock/units changed in a way that wasn’t expected in the baseline.
Deterministic API diffing tools like diffy generally rely on multiple runs against the reference in order to detect differences. This approach is good at detecting things in the reference which always vary. In our model, such variance is represented by entropy.
However, these tools can be confused by non-determinism which isn’t very entropic. For example, suppose that on average 2 out of 3 times some state field has value Ready and is otherwise NotReady. Then, the reference comparisons in diffy may both have NotReady and the candidate may be Ready. The fact that the candidate differs from the reference and the reference runes do not not differ between them does not suffice to conclude the difference is relevant nor that there is an incompatibility. Our model can by contrast see that the candidate value may well have been part of the baseline, and so is correctly classified as irrelevant.
We have presented a method of modeling arbitrary JSONs in a hierarchical structure which allows us to classify the relevance of structured differences between reference and candidate requests and responses. The functionality which results is similar to tools such as https://github.com/twitter-archive/diffy. However, there are several benefits of our approach.
First, diffy requires setting up multiple reference runs for each diff computation. Our system by contrast is based on a model of the reference which, although it is ongoing, it need only be deployed once. Each diff run requires only 1 run of the reference, not 2 or more. Second, relevancy weights can filter out irrelevant diffs that diffy cannot. Third, the models themselves have a multitude of possible applications, from mocking to fuzzing to generation and more.
However, our system is limited to REST HTTP. It cannot address streams, GraphQL, GRPC, etc. For systems without streaming but with structured data, it would not be difficult to translate them to the JSON captures presented here. At the same time, such alternative protocols have different needs. For example, internal REST HTTP APIs often lack or have only very limited schema associated, but GRPC and GraphQL do not, and one of the highlights of our approach is that it can identify schema changes without a schema. As a result, we leave as future work how to best analyze and present on-the-wire changes for these alternative protocols.
Get the latest updates from Signadot

